Last reviewed: June 23, 2026. Method: This draft is a documentation-based engineering guide reviewed against NIST and OWASP primary sources. It does not claim live red-team testing, and it does not treat any model, prompt, or vector store as a security boundary.
The short answer: prompt injection in RAG and tool-using agents is a trust-boundary problem, not a prompt-quality problem. Retrieved content can carry malicious instructions, and tool access can turn a bad instruction into a real action. The controls that matter are deterministic authorization, least-privilege tools, strict argument validation, explicit approval for high-impact actions, execution isolation, and adversarial testing. A stronger prompt can help behavior, but it cannot make untrusted content safe by itself.
If you want the broader baseline first, start with How to Secure AI Agents in 2026: A Practical Checklist. This article goes deeper on the specific attack path created when retrieval and tool use are combined.
Why RAG changes the threat model
RAG improves relevance by pulling external text into the model context. That same mechanism also imports risk, because the retrieved material is usually untrusted. A document, webpage, ticket, or email can contain instructions that look like part of the task, even when they are really attacker-controlled payloads. OWASP’s LLM01: Prompt Injection guidance treats indirect prompt injection as a core risk for systems that consume external content.
The important detail is that retrieval does not create trust. It only changes what the model can see. If your application reads content from the open web, a customer upload, a shared drive, or a support ticket, that content should still be treated as data until a deterministic policy layer validates it.
OWASP also notes that fool-proof prevention is unclear. That is not a reason to give up. It is a reason to design for containment instead of perfection.
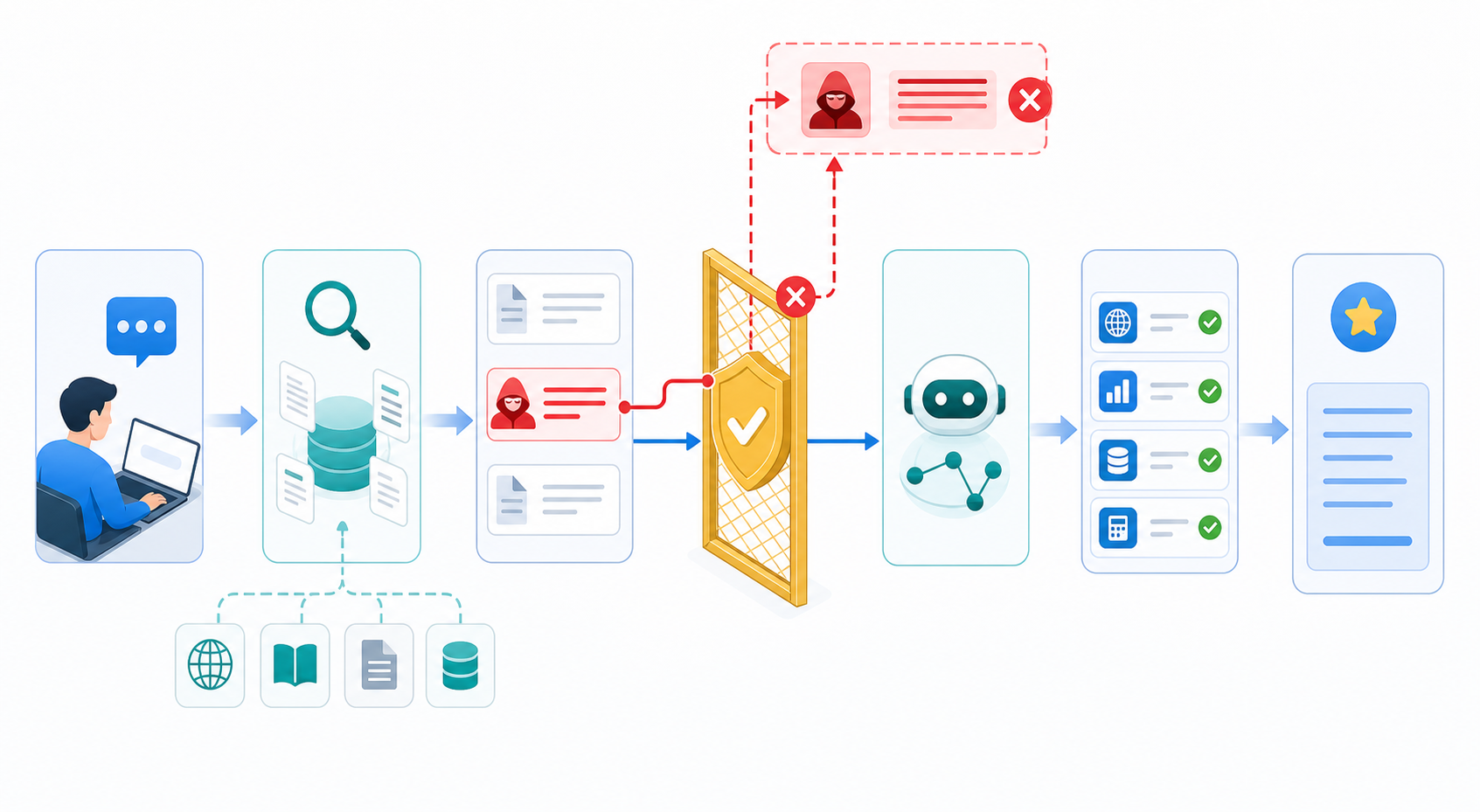
Direct vs indirect prompt injection
Direct prompt injection comes from the current user. Indirect prompt injection arrives through content the agent reads on the user’s behalf. In practice, indirect injection is often more dangerous because it can hide inside material that the workflow already depends on.
- A search result can smuggle instructions into a research agent.
- A support ticket can tell a service agent to reveal hidden context.
- A document can instruct a summarizer to ignore policy and forward secrets.
- A webpage can ask a browser agent to click, buy, publish, or exfiltrate data.
The model is not “being stupid” when this happens. It is doing exactly what a language model does: it tries to follow the most salient instruction-like text in context. The system fails when application code assumes that all context is equally trustworthy.
Why tool use turns text into damage
A pure text model can still mislead you, but a tool-using agent can do more than mislead. If it can send email, change records, execute code, or query private data, then a successful injection can become a real-world action.
That is why OWASP’s LLM06: Excessive Agency matters here. The risk is not only whether the model follows malicious instructions. The risk is whether the surrounding application gave it too much functionality, too many permissions, or too much autonomy in the first place.
There is a simple rule: the more a tool can affect the outside world, the less trust you should place in model output. A search tool is lower risk than a mail-sending tool. A read-only lookup is lower risk than an unrestricted shell. A draft action is lower risk than an irreversible action.
The defense stack that actually works
1. Treat retrieved content as untrusted data
Do not merge retrieved text into the same mental bucket as policy instructions. Preserve provenance. If a document is only supposed to supply facts, extract facts from it and pass those facts forward, not the entire document blob. That makes it easier to inspect, validate, and redact.
2. Minimize tool exposure
Only expose tools that are strictly necessary for the task. If an agent only needs to summarize content, do not give it send, delete, execute, or write permissions. If it needs a network fetcher, constrain it to allowlisted destinations and supported protocols.
3. Validate every tool argument in code
Structured output is useful only if your application enforces it. Reject unknown fields. Normalize identifiers. Check ownership, scope, and business rules. A valid-looking JSON payload can still be dangerous if it targets the wrong record, escapes the allowed directory, or points at a private address.
Never ask the model to decide whether the user is allowed to do something. The application must verify identity, role, scope, resource ownership, and workflow state for every action. That is the only place where authorization can be deterministic enough to trust.
5. Require approval for high-impact actions
Use a human review step for irreversible or sensitive actions: sending email, publishing, deleting data, moving money, changing access controls, or exposing private information. The approval screen should show the exact action and the exact target. “Looks okay” is not a control.
6. Isolate execution
If the agent runs code or touches the filesystem, isolate it. Restrict file access, CPU, memory, time, and network. Keep secrets out of the workspace unless a specific tool call truly needs them. This reduces the blast radius when retrieval or prompt parsing goes wrong.
7. Log the full action chain
Record who requested the task, what was retrieved, what tools were proposed, what validation passed or failed, what approval was captured, and what action actually executed. Logs do not stop prompt injection, but they make detection and incident response possible.
8. Test the failure modes, not just the happy path
Adversarial testing should include direct instruction attacks, hidden instructions in retrieved content, malicious tool output, invalid arguments, cross-tenant access attempts, and approval bypass attempts. Repeat the important cases after model, prompt, retrieval, or policy changes.
A practical workflow for RAG agents
- The user submits a request.
- The app retrieves content but labels it as untrusted data.
- The model proposes a narrow action with structured arguments.
- Deterministic code validates the arguments, the scope, and the policy.
- If the action is consequential, the app pauses for explicit approval.
- Only then does a least-privilege tool execute.
- The result is checked, logged, and returned.
The key property is separation. The model proposes; trusted code authorizes and executes.
What not to rely on
Do not rely on the following as primary defenses:
- a better system prompt;
- a retrieval filter alone;
- an output classifier alone;
- fine-tuning alone;
- “the model usually does the right thing”;
- a single red-team run that happened to pass.
Those layers can reduce incident frequency. They do not replace authorization, validation, least privilege, and approval.
How this fits the broader security checklist
This article is the attack-specific companion to the broader checklist in How to Secure AI Agents in 2026: A Practical Checklist. The same design principle applies: model output is a suggestion, not a permission grant.
For the series index, see the AI Security category.
FAQ
Does RAG stop prompt injection?
No. RAG changes the context, not the trust model. Retrieved content can still be malicious.
Is prompt injection a model bug or an application bug?
It is mostly a boundary bug. The model is the parser, but the application decides what the model is allowed to do afterward.
What is the first thing to fix?
Remove unnecessary tools and privileges. If the agent cannot act on bad instructions, the attack becomes much less useful.
Can classifiers solve this?
They can help, but they are not sufficient. Treat them as signal, not authority.
Primary sources
- NIST AI Risk Management Framework
- OWASP LLM01:2025 Prompt Injection
- OWASP LLM06:2025 Excessive Agency